6月4日,Nature子刊Scientific Data正式上线了一篇题为“Harmonizing existing climate change mitigation policy datasets with a hybrid machine learning approach”的论文,一个涵盖七万多条政策的全球规模最大的气候政策数据库也同步向全球公开。这是复旦大学大数据学院吴力波教授带领的研究团队,历时三年研发的全球最大规模的气候变化减缓政策数据库(Global Climate Change Mitigation Policy Dataset,简称GCCMPD)。
为什么要构建这样一个数据库?其根本目标是要能够帮助各国气候政策的制定者和学者开展更加系统的基于全球视角的气候政策分析。数据库的上线,意味着可以在全球尺度上看到全球气候政策的特征,相当于有了一个全球气候政策的百科全书。
COP28联合国气候变化大会针对《巴黎协定》的盘点证明,全球气候渐缓的步伐正处于摇摆状态,现有气候政策的有效性还需要大大加强。但是由于各国政体、经济社会环境、资源禀赋差异巨大,各国之间在气候政策的选择上存在着复杂的博弈交互关系。缺乏全面、客观、系统的气候政策数据基础,阻碍了在全球层面更加公平的评价各类政策的减排强度、经济社会影响等,使得气候治理能力较弱的国家无法有效学习先进经济体的经验,也无法评估各国、各类气候政策之间,以及气候政策和其他政策之间存在复杂的内生交互和动态关联的关系,政策分析的缺失在很大程度上妨碍了各国气候政策的优化设计,也给国际气候合作机制的发展形成障碍。
就在6月5日世界环境日,联合国秘书长古特雷斯呼吁国际社会就气候变化立即采取行动,减少排放、增加气候投融资,同时他强调没有一个国家能够孤立地解决气候危机,已经到了需要全球各国全力以赴的时刻。

GCCMPD数据库汇集了全球、区域以及特定行业政策制定层面的丰富信息,涵盖了216个实体、共计73, 625项气候变化减缓政策。特征标签涵盖部门、工具、目标、法律约束有效性、政策持久性、作用范围等维度,是目前全球已发布的同类数据库中,覆盖政策最全、特征分类最细、多政策交叉分析最强的。为全球气候变化减缓政策的跨地区比较分析、特征挖掘、传播影响识别、多目标权衡研究、政策实施的制约因素、政策组合的协同效应等研究提供强有力的数据支持。
目前,包括世界气候变化法律数据集(CCLW)、国际能源署(IEA)政策和措施数据集和气候政策数据集(CP)等全球数据集已经对气候政策数据构建进行了初探。然而,随着新的气候实践的出现和更先进的数据处理方法的出现,气候政策研究逐步多样化,现有的全球气候政策数据集尚有明显的不足之处,这些数据集大量依赖人工手段收集分析处理,导致数据更新缓慢、去重困难、政策内涵不清等问题,缺乏针对具体部门的政策工具分类特征的精准识别,无法针对具体部门政策组合进行深入研究,政策版本和覆盖范围的差异也会削弱以政策密度为衡量指标的研究的稳健性,大量研究对政策强制属性无法精准识别,机械的将法律与大量支持性政策和较弱的政策区分开来,导致支持性政策的作用被忽视。
为此,吴力波研究团队使用多层流程提供了从数据识别、数据采集、数据处理、人工核查,再到数据拓展以及相关可能应用的统一方法学框架。通过自动化的数据工程,汇集全球数据集、区域数据集、专注于技术、政策工具和立法等专业领域的数据集等多重数据来源,解决了当前气候政策数量、覆盖范围不足的问题。
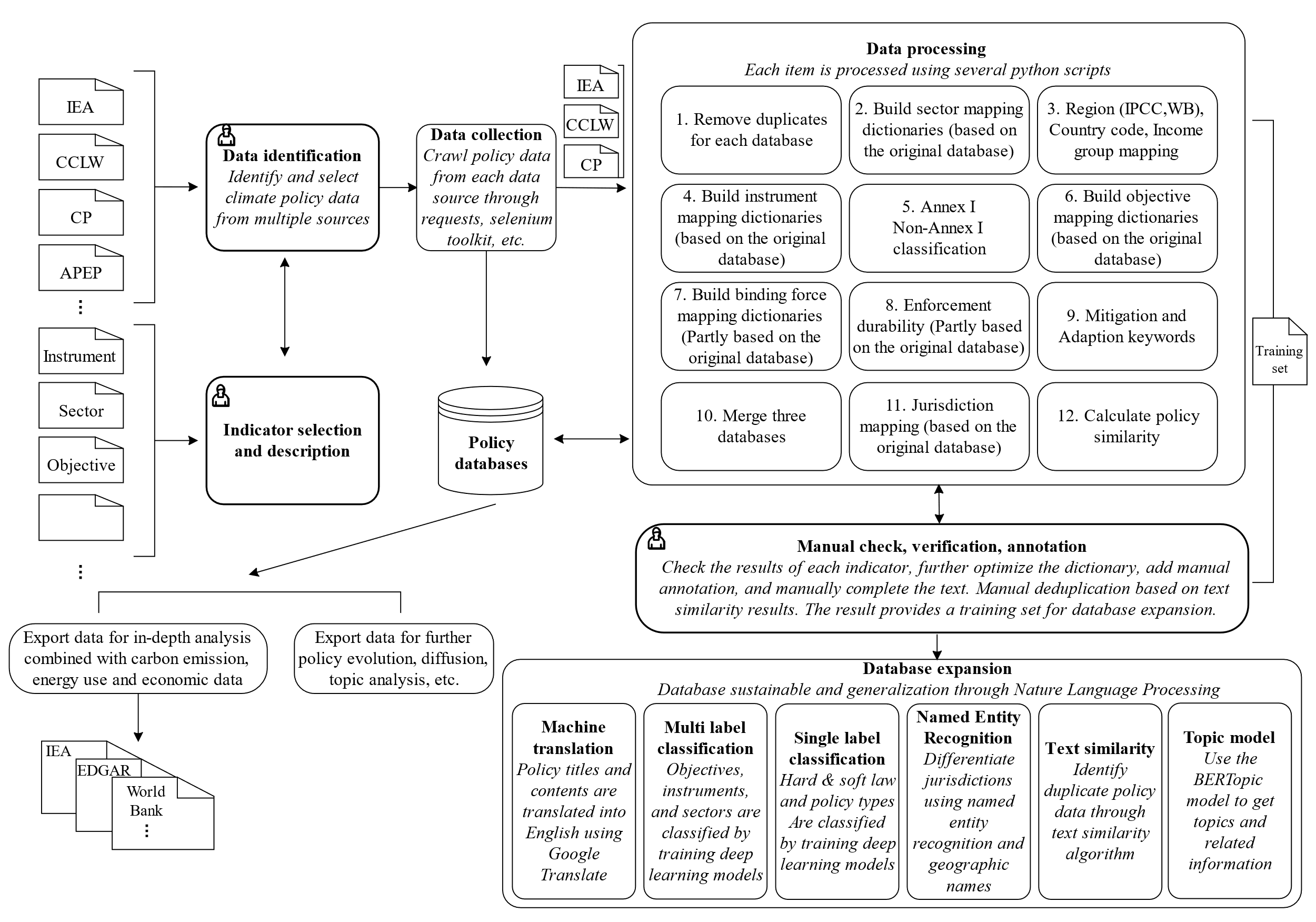
图1:GCCMPD 构建框架概
此外,考虑到当前数据集有数据重合、分类标准不统一、分类细致程度仍然欠缺、大量依赖人工分类等问题,研究团队通过政策特征指标选择步骤,确定政策目标部门、政策工具、政策协同效益目标、法律约束力、行政/立法、管辖权等核心政策特征的分类标准;通过机器学习映射结合人工校验,实现了三大核心数据集(CCLW、CP、IEA)统一分类、去重和人工校对;最后,通过融合应用机器翻译、多标签分类、单标签分类、命名实体识别、文本相似度和主题模型等多种先进机器学习方法,依靠政策标题和内容完成了数据集构建,解决了人力成本高、更新速度慢、扩展困难等问题。
Method/Package | Natural Language Processing (NLP) Task | GCCMPD indicator/purpose of model |
Google translation | Machine translation | Uniform policy title and content in English |
ClimateBERT | Multilabel classification | Sector, Instrument, Objective |
single-label classification | Binding force; Executive/legislative | |
"en_core_web_trf" & "countryinfo" | Named Entity Recognition (NER) | Jurisdiction |
BM25 & "en_core_web_trf" | Text similarity | Automatically find duplicates |
BERTopic | Topic Modelling | The topic of each policy |
表1:GCCMPD 使用的模型和方法
与现有数据集相比,GCCMPD结合现有数据集和混合机器学习方法,构建了一个多维度系统、完整的特征标签体系,填补了现有气候政策数据集与日益增长的研究需求之间的空白。首先,GCCMPD可用于构建更准确的政策指标。GCCMPD在数据收集上具有全面性,相较于其他单一数据集,其政策记录更为丰富,能够显著减少政策遗漏,从而降低对实体减缓气候变化努力的低估风险。其次,GCCMPD提供了衡量不同部门产出的定量工具,有助于评估和比较各行业在气候变化减缓方面的贡献。再者,GCCMPD包含的政策相似性信息,为研究者提供了探索气候政策传播路径和影响因素的有效数据支持。最后,GCCMPD涵盖了硬法律(具有法律约束力的政策)和软法律(非强制性的政策指导或建议)的详细信息,为研究硬法与软法之间的转换机制以及不同法律工具对温室气体排放影响提供了数据基础。
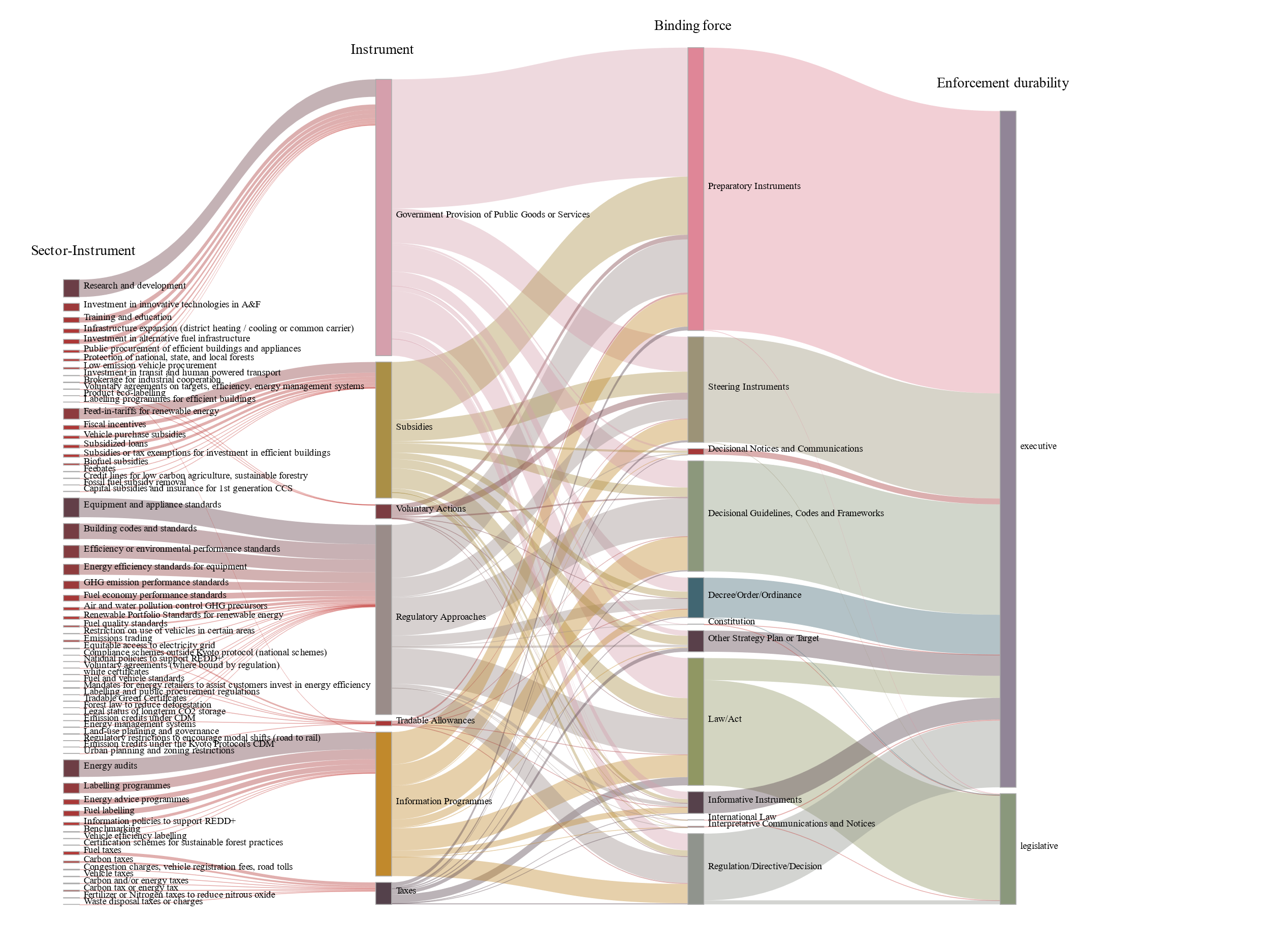
图2:政策工具与部门政策工具
合并气候政策数据结果发现,政策工具与部门政策工具、政策部门与政策子部门、政策目标与政策子目标均集中在某些项目上,存在分布不均且部分政策严重不足的现象。具体来说,政府提供服务与购买是使用最频繁的政策工具,政策部门集中于能源部门。尽管政策协同效益目标相对均衡,但仍以经济目标居多。这一发现也为各国气候治理提供了明确的方向。
该研究是人工智能与气候政策科学深度交叉的成果,为人工智能在气候政策科学领域的应用提供了宝贵的新视角。该研究不仅有效拓展了政策科学研究的数据基础,还为全球气候政策的深度比较分析开辟了新思路。据了解,吴力波团队正在将该数据集与更多高质量科学语料进行汇聚,基于生成式AI与多智能体建模,开发气候大模型,从更多维度深入推进气候与能源领域中人工智能的交叉研究。
复旦大学大数据学院教授吴力波为第一作者及通讯作者,主要作者为复旦大学大数据学院博士研究生黄之豪、王玉世、张兴。
论文链接:https://www.nature.com/articles/s41597-024-03411-z




