自然语言处理研究是用人工智能来处理、理解以及运用人类语言,因此被誉为人工智能皇冠上的明珠。而信息提取是自然语言处理的一个重要分支,指从非结构化文本中自动提取结构化信息,这在当今社会生活中有着广泛运用。比如在线客服自动回复机制、网络信息监测系统及人工智能机器人的对话机制等等,其对商业、医学、通信、审计、媒体、政府等多种文字密集型行业应用领域产生了重要作用。
然而,现有的信息提取模型往往需要针对特定标注数据集来训练模型,而忽略了大量其他的开源标注数据集。这种方式导致现有模型无法适应全新的场景,如在线问诊机器人可能无法很好适应金融投资领域,导致模型的鲁棒性较差,这就要求开发者对其重新进行大量标注,工作量大且效率较低。

针对以上问题,复旦大学计算机科学技术学院自然语言处理实验室(FudanNLP)提出或可用已有的信息提取数据集,实现提高模型在当前场景的性能的同时大大减少所需要的标注样本数目,建立结构化提取任务的统一迁移学习框架。该成果汇总于“A Multi-Format Transfer Learning Model for Event Argument Extraction via Variational Information Bottleneck”中,已被COLING 2022以长文oral形式录用,并获得大会杰出论文奖,论文第一作者为博士后周杰,指导老师为张奇教授和黄萱菁教授。
建立多格式迁移模型,实现多场景运用
目前大部分信息提取工作都是基于不同的数据集设定其特定的模型结构,各个场景的标注规范不统一。以标注对象“时间”为例,有的场景中将“某日”视作时间,而有的场景则将“某日几时几分”这个整体视作时间,理解的差异导致标注的冲突。同时,结构化提取任务具有复杂性,标注空间较大,如部分场景重点标注时间,部分场景重点标注地点,以上两个场景的模型在“重点关注人物”的场景中就无法运行,因此只能由开发者重新标注新的数据集以训练模型。复旦大学研究者们跳脱出固定思维,尝试利用不同场景的差异,使模型博采众长,在大量的已标注数据上进行基础训练,通过迁移共享表示大大减少在新场景中的数据标注量。
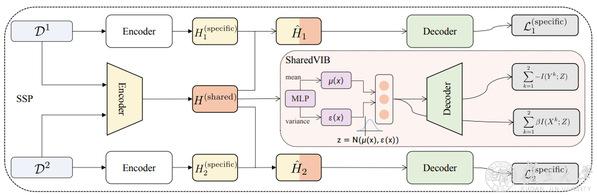
为迁移不同格式的结构化数据集的知识,研究者们构建基于变分信息瓶颈的多格式迁移模型。该共享-特定的提示模型用于从不同格式数据集学习格式特定和共享的表示,使用统一的框架对不同格式的结构化数据集进行提取。而后,利用变分信息瓶颈来约束模型学习格式共享的表示。最终,该共享-特定的提示模型成果在三个标准数据集上取得了SOTA(state-of-the-art,即在该项研究任务中,目前最先进的模型)的结果。该成果将推动通用模型的建立,在减少数据标注的情况下,利用已有的结构化的标注数据进一步提高模型的性能。
从机器人情感分析研究出发,成功优化“子任务”
国际计算语言学会议(International Conference On Computational Linguistics,COLING),是自然语言处理和计算语言学领域的顶级会议,每两年举办一次。本次COLING会议共吸引了超过2000篇投稿,最终共录用522篇长文、112篇短文,仅11篇获得杰出论文奖。于周杰和其所属的张奇、黄萱菁团队而言,本次奖项的获得是对他们多年致力于科研的肯定,同时也为他们继续深耕自然语言处理领域昭示了光明的前路。
本文的第一作者周杰曾将机器人情感分析作为自己博士阶段的研究方向,他希望使人工智能胜任更复杂的任务,让机器不仅仅拥有智商,也能够拥有情商。然而在研究的过程中,周杰发现,尽管预训练模型等新技术的出现,能够推动常识和情感的常识提取效果的提高,但是其效果也仅仅是“将数据标注从一万条缩减为一千条”。周杰认为如此训练模型的成本依旧有些高,如何推动模型更快适应全新的领域便成为周杰孜孜求索的方向。
自然语言处理实验室(FudanNLP)合影
2021年6月,周杰进入复旦大学计算机科学技术学院自然语言处理实验室(FudanNLP)开始自己的博士后研究阶段。从不给定的实体中去判断情感是该团队长期以来的研究方向,受此启发,周杰开始尝试在信息提取领域中做与情感结合的研究,率先优化“子任务”。
从构思到论文成型的一年中,周杰认为团队给予了自己全方位的帮助。据他介绍,课题组不但每周举办组内分享会,通过个人报告的形式提供不同研究方向的组员以思想碰撞的机会,而且时常邀请各领域专家分享最新研究情况,全面了解行业尖端研究的困境、成果与解决方法,极大开拓了其眼界。同时,周杰也坦言,张奇教授和黄萱菁教授的指导令自己受益良多,他将导师们的帮助概括为“迷茫时为我指明方向,走错道路时及时拉我一把”。
据悉,复旦大学自然语言处理实验室是我国最早开展自然语言处理和信息检索研究的实验室之一。40余年来,在自然语言处理底层分析、文本检索、自动问答、社会媒体分析等方面都取得了一系列的研究成果,多年在国家及省部委支持下,发表大量高水平国际期刊和会议论文,其中包括中国计算机学会推荐的A/B类国际会议和期刊论文(ACL, SIGIR, IJCAI, AAAI, NIPS, ICML等)论文150余篇;参加多项国内外评测,如在自动问答国际评测TREC/QA中获得第3名,在文本蕴涵评测RITE和阅读理解评测SQUAD都位居前列。
谈及对未来的规划,周杰表示将继续深耕科研领域,使情感机器人具备多领域的适应性,推动与人顺畅交际的实现。“未来我想将该研究开发为一款高性能高鲁棒的通用信息提取框架,从而服务于知识图谱构建、舆情分析等下游任务。”周杰笑言道,“希望能够创建人们愿意与之沟通的对话系统,而不是让人们与之聊上三两句话就发送‘人工客服’的申请。”




