近日,复旦大学类脑智能科学与技术研究院青年研究员单洪明团队联合计算机科学技术学院张军平教授团队聚焦人脸识别和无监督深度聚类,在全球人工智能领域顶尖期刊《IEEE模式分析与机器智能汇刊》(IEEE Transactions on Pattern Analysis and Machine Intelligence,TPAMI)发表两项重要成果。

图1:IEEE Explore (Early Access)

图2:IEEE Explore (Early Access)
跨年龄人脸识别与合成:一个多任务学习框架和新基准
人脸识别多年来一直是计算机视觉领域的研究热点。尽管近几年人脸识别取得了显著的成功,但如何最大限度地减少年龄变化的影响是当前人脸识别系统在许多实际应用中正确识别人脸的一个长期挑战,例如追踪长期失踪的儿童。因此,实现年龄不变的人脸识别 (Age-Invariant Face Recognition, AIFR)具有重要意义。然而,AIFR 在以下三个方面仍然极具挑战性。首先,当跨年龄人脸识别中的年龄差距变大时,年龄差异会主导面部外观,从而显著影响人脸识别性能。其次,面部年龄合成(Face Age Synthesis, FAS)是一个复杂的过程,涉及面部老化/年轻化 (也称为年龄增长/衰退)。 而且面部外观在很长一段时间内会发生巨大变化,并且因人而异。最后,要获得大规模的成对人脸数据集来训练模型,在保持身份的同时渲染具有自然效果的人脸是不可行的。
为了解决上述问题,当前的方法可以大致归纳为两类:生成模型和判别模型。给定人脸图像,将不同年龄组的人脸转换为同一年龄组,以最小化年龄变化对人脸识别的影响。然而,因为合成的人脸会有很强的伪影,并且人脸的身份也发生了变化,所以 AIFR 的性能无法得到提高。另一方面,判别模型侧重于通过从混合的人脸信息中分离身份相关的信息来提取年龄不变特征,从而使人脸识别系统仅使用身份相关信息。尽管这些模型在 AIFR 中取得了良好的性能,但它们不能像生成方法那样为用户(例如警察)提供视觉结果,以进一步验证身份,这可能会损害许多实际应用决策过程中模型的可解释性。
本文提出了一个统一的多任务框架来联合处理跨年龄人脸识别和合成两个任务,称为MTLFace。它可以学习用于人脸识别的年龄不变的身份表征,同时实现用于模型解释的令人满意的人脸合成。具体而言,我们提出了一种基于注意力的特征分解,以空间约束的方式将混合的面部特征分解为两个不相关的分量身份特征和年龄相关特征。与实现组级合成的传统one-hot编码不同,我们提出了一种新的身份条件模块来实现身份级的合成,该模块可以通过权重共享策略提高合成人脸的年龄平滑度。受益于所提出的多任务框架,我们利用年龄合成中的高质量合成人脸,通过一种新的选择性微调策略进一步提高人脸识别。此外,为了推进这两个任务,我们收集并发布了一个带有年龄和性别标注的跨年龄人脸数据集,以及一个专门为追踪长期失踪儿童而设计的新基准。在五个基准跨年龄数据集上的广泛实验结果表明,MTLFace在识别与合成中都比最先进的方法产生了更好的性能。我们在两个流行的通用人脸识别数据集上进一步验证了 MTLFace,在自然场景下人脸识别方面获得了竞争性的性能。
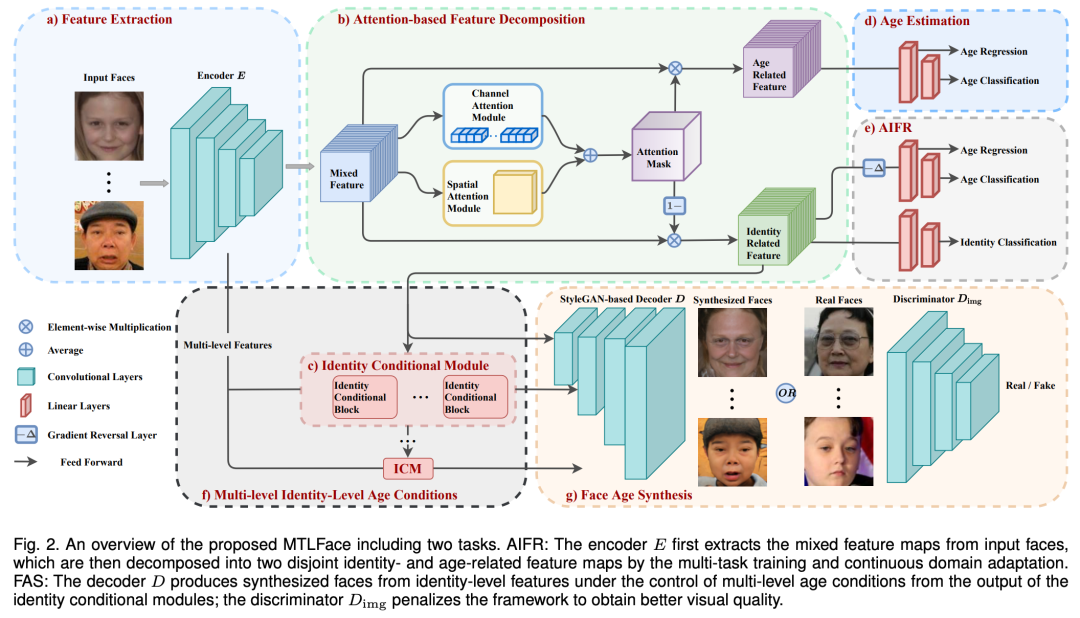
图3:多任务学习框架的示意图,展示了本文提出的多任务学习框架。对于 AIFR ,编码器 E 首先从输入人脸中提取混合特征图,然后通过多任务训练和连续域自适应将其分解为两个不相交的身份和年龄相关特征图。对于 FAS,解码器 D 根据身份条件模块的输出和多级年龄条件的控制下生成不同年龄的人脸,而鉴别器 Dimg 惩罚整个框架以获得更好的视觉质量。
基于原型对比和正样本采样的深度聚类算法
深度聚类旨在学习图像的表征并以端到端的方式执行聚类。现有的深度聚类方法严重依赖于对比学习。具体而言,它们通常在对比学习的基础上,专门设计损失函数或者使用预训练模型学习具有判别性的表征。然而尽管实现了满意的聚类效果,基于对比的方法通常需要大量的负样本来学习表征,使得所有样本的表征都能很好地分离。负样本不可避免地导致类冲突问题,即来自同一类别的不同样本被视为负例并被错误推开,进而损害下游聚类任务。
关于这个问题的另一个观点是将典型的对比度损失分为两个项:1)对齐项以拉近正样本,2)均匀项以通过推开负样本来鼓励表征在单位超球面上均匀分布。显然,第二项会引入类冲突问题,因为构造的负样本对可能不是真正的负例。与对比学习不同,非对比学习只有对齐项,直接使用一个数据增强的表征来预测另一个数据增强。非对比学习可以避免类别冲突问题,但是由于缺少负例,无法保证学习到均匀的表征,这可能导致下游聚类的崩溃,即大多数样本被分配到很少的类别上。当结合当前最先进的深度聚类方法或者引入的额外聚类损失,这种现象甚至会恶化。
本文提出了一种新的基于原型对比和正样本采样的端到端深度聚类方法,可以集成这两类算法的优势,称为ProPos。具体而言,我们首先最大化原型之间的距离,促进了不同类别均匀的分布在球上。其次,我们将样本的一个数据增强与另一个增强的邻域对齐,以提高簇内紧凑性。ProPos的优点有可避免的类别冲突、均匀的表征学习、簇间可分离以及簇内紧凑。通过在端到端的期望最大化框架中优化,我们提出的ProPos算法在大量数据集上取得了优异的性能。该算法将助力在无标记数据中自动挖掘内在的模式。
源代码在https://github.com/Hzzone/ProPos,我们提供了常见自监督学习在深度聚类上的实现,以及基于 PyTorch 的 k-means 和 GMM 实现。
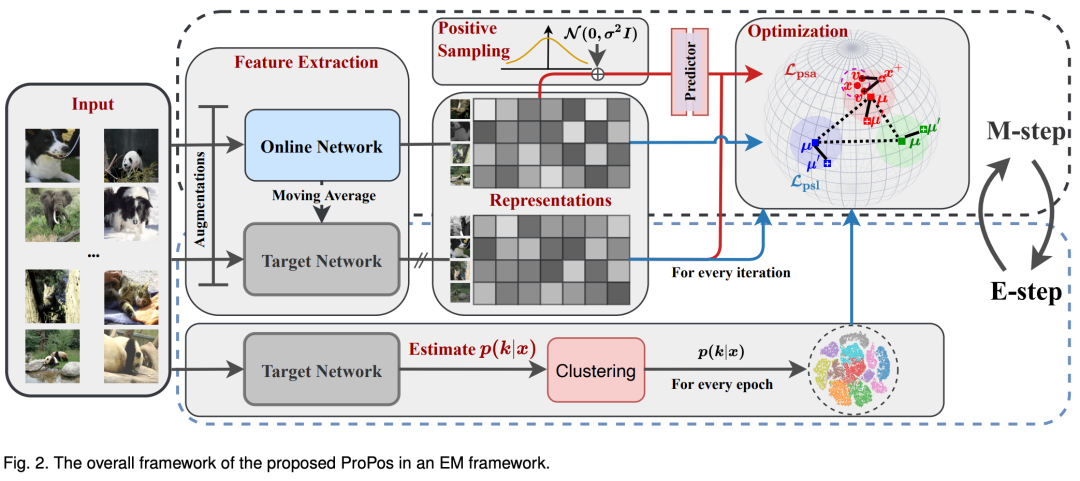
图4:整体框架,我们使用EM 框架来优化 ProPos,其中 E 步和 M 步详细如下: E-step: 对表征进行 k-means 聚类以得到伪标签;M-step: 优化本文提出的两个损失函数
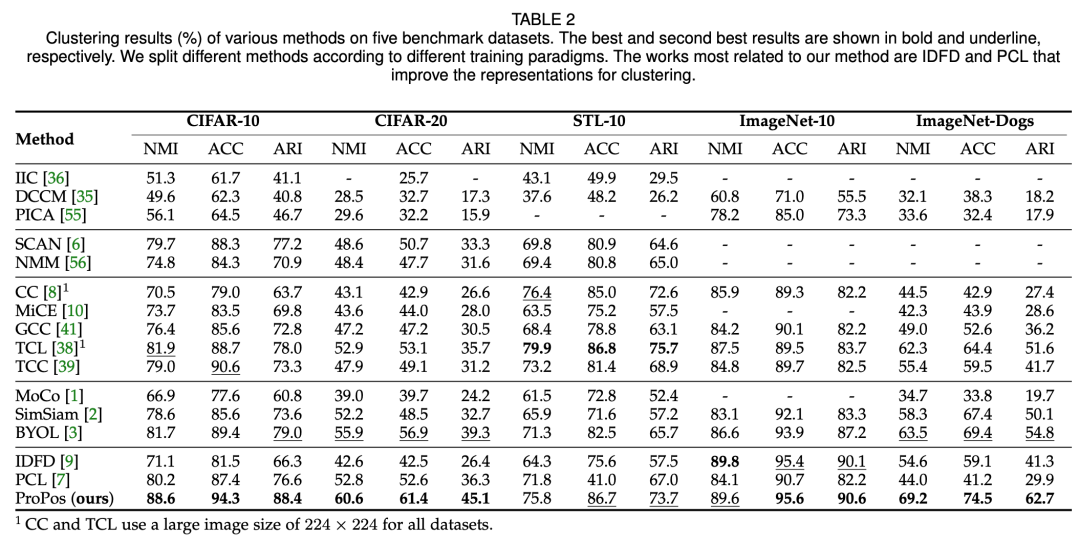
图5:性能对比,我们提供了 ProPos 在多个深度聚类的基准数据集上的性能对比,ProPos 取得了非常大的提升
复旦大学类脑智能科学与技术研究院单洪明青年研究员为这两篇文章的通讯作者,复旦大学计算机科学技术学院博士研究生黄智忠为第一作者,由单洪明青年研究员和计算机科学技术学院张军平教授共同指导。该研究得到了国家自然科学基金委、上海市脑与类脑智能基础转化应用研究市级重大专项以及上海市科委科技创新计划等的经费支持。
原文链接:
https://ieeexplore.ieee.org/document/9931965
https://ieeexplore.ieee.org/document/9926200




